

既存のAPI Lambda をLambdalithに置き換える現在運用しているプロジェクトのひとつにバックエンドにAPI GatewayとLambdaを利用したシンプルな構成をServerlessFrameworkで構築しているものがあります。
プロジェクトが大きくなるに従って、CloudFormationの1スタックのリソース上限500に抵触することが多くなってきました。
これまではAPI Lambdaを用途ごとにuser系やsite系などに分けて、スタックを分割してきましたが、どこかに偏ってしまうこと増え、どっちつかずのAPIなど管理も手間になってくることが多くなりました。
そこで今回は、これまでAPI Lambdaとして、一つのエンドポイントごとに一つのLambdaを構築していた構成をAPI Gatewayに紐づくLambdaは一つだけとする、いわゆるLambdalithの構成にリプレイスしていきます。
- CloudFormationのリソース上限エラーに対する対応
- ServerlessFrameworkでAPIGateway × LambdaをLamdalithで構築する方法
- 既実装済みのLambdaコード(Python)に極力手をかけず、移行する方法
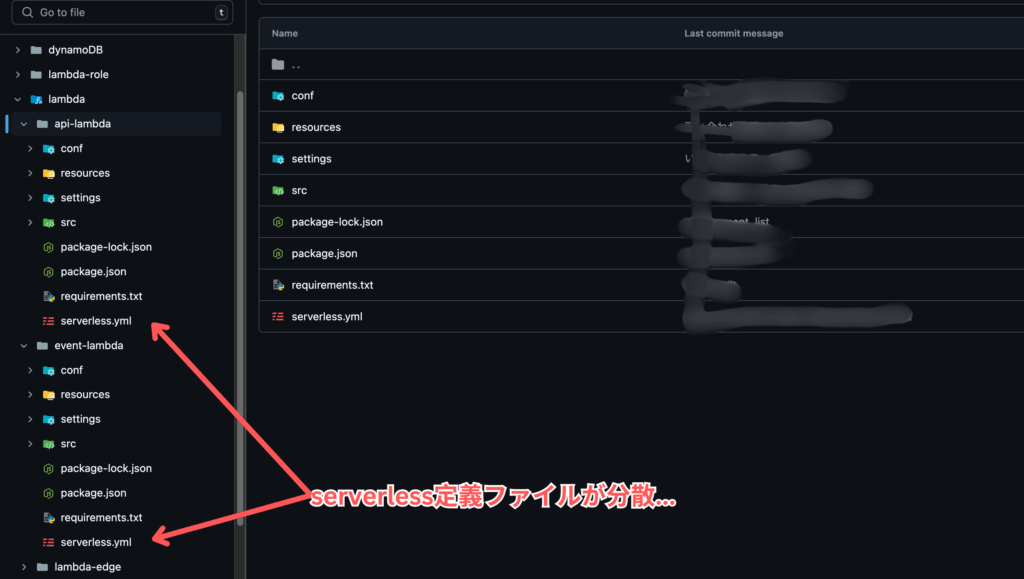
現在の構成
現在のリソースの構成です。
ServerlessFrameworkを使用しているため、スタックごとにserverless.yamlを作っていくことも、デプロイのたびにディレクトリ移動など面倒に感じる点です。
改修後の構成
今回目指す最終的な構成は以下の通りです。Lambdalithとしてエンドポイントをまとめ、APIのルーティングはpowertoolsを使用します。
更に今回は、もともとLambda関数として作成していたそれぞれの関数ファイルがあるため、これらのファイルには基本的には手を付けず、なるべく簡単な移行ということに注力します。
API GatewayとLambda関数の再定義
まずは、ServerlessFrameworkの定義でAPI GatewayとLambda関数を新規で作成します。
DBとして、RDSを利用しているプロジェクトなので、VPC Lambdaとして構築していきます。 VPCの設定などはこれまで利用していたものをそのまま利用します。
また、旧API LambdaでもINVOKEとして利用していたものは、今回の移行の対象とせず、arnを環境変数として付与しておき呼び出す形にしていきます。
service: sls-v2
provider:
name: aws
runtime: python3.11
region: ${opt:region, "ap-northeast-1"}
versionFunctions: false
logRetentionInDays: 30
stage: ${opt:stage, self:custom.defaultStage}
tracing:
apiGateway: true
lambda: Active
environment:
POWERTOOLS_LOG_LEVEL: INFO
POWERTOOLS_LOGGER_SAMPLE_RATE: 0.1
POWERTOOLS_LOGGER_LOG_EVENT: true
POWERTOOLS_SERVICE_NAME: example
role: arn:aws:iam::123456789012:role/lambda-role
functions:
apiFunction:
handler: src/lambdalith.lambda_handler
description: API handler root functions
memorySize: 256
timeout: 30
package:
individually: false
layers:
- arn:aws:lambda:${self:provider.region}:017000801446:layer:AWSLambdaPowertoolsPython:33
environment: ${file(./_configs/lambda_environments/common.yaml)}
vpc: ${file(_configs/lambda_vpc.yaml)}
events:
- http:
path: /{proxy+}
method: any
cors: true
authorizer:
type: COGNITO_USER_POOLS
authorizerId:
Ref: ApiGatewayAuthorizer
resources:
Resources:
ApiGatewayAuthorizer:
Type: AWS::ApiGateway::Authorizer
Properties:
Name: Cognito
RestApiId:
Ref: ApiGatewayRestApi
IdentitySource: method.request.header.Authorization
Type: COGNITO_USER_POOLS
ProviderARNs:
- 'arn:aws:cognito-idp:XXXXXXXXXXXXXXX'
- 'arn:aws:cognito-idp:YYYYYYYYYYYYYYY'
package:
include:
- src/lambdalith.py
- src/**
- requirements.txt
exclude:
- ./**
plugins:
- serverless-python-requirements
custom:
pythonRequirements:
dockerizePip: true
slim: true
defaultStage: dev
STAGE_NAME:
environment:
dev: ${file(./_configs/lambda_environments/dev.yaml)}
prod: ${file(./_configs/lambda_environments/prod.yaml)}
# invoked lambda function from sls-v1
INVOKE_FUNCTION_SES_SEND_EMAIL_NEW_POST_FORM:
environment:
dev: ${file(./_configs/lambda_environments/dev.yaml)}
prod: ${file(./_configs/lambda_environments/prod.yaml)}
Lambdalithの作成
lambdalithの関数定義を作っていきます。
今回はすでにLambda関数ファイルが個別にあるため、それらのファイルをimportしておき、実行する対応をしておきます。
ひたすらimportしていくのでかなり面倒でしたが、途中まで書けばcopilotやcursorなりAIエディッターがいい感じにサジェストしてくれるので、幾分か楽ではありました。
# 共通のパッケージ
import requests
from requests import Response
from aws_lambda_powertools import Logger, Tracer
from aws_lambda_powertools.event_handler import APIGatewayRestResolver
from aws_lambda_powertools.logging import correlation_paths
from aws_lambda_powertools.utilities.typing import LambdaContext
from src._utils.response_utility import response_builder, parse_body
# ソースコード
# #---既存APIのルートパスに合わせて整理しておく。
# #---既存はすべてhandlerなのでリネームしておく。
# /sites
from src.sites.get_sites import handler as get_sites_handler
from src.sites.get_sites_branch import handler as get_sites_branch_handler
from src.sites.get_site_members import handler as get_site_members_handler
# /tasks
from src.tasks.get_tasks_all import handler as get_tasks_all_handler
from src.tasks.get_tasks_bookmark import handler as get_tasks_bookmark_handler
# ...import以下略
Lambda関数を外部ファイル化しましたが、もともとのLambda関数のevent, contextに合わせてLambdalith側で必要な情報を渡して、import関数を実行するために実行関数を一つ用意していおきます。
# 共通メソッド:ハンドラの呼び出しとパスパラメータの付与
# #---既存Lambda関数を再利用のため、event, contextを同じように統一。
def execute_handler(handler_func, path_params=None):
# app.current_eventを直接操作できないので、別のオブジェクトとして作成
event = {
"headers": app.current_event.headers,
"queryStringParameters": app.current_event.query_string_parameters,
"pathParameters": app.current_event.path_parameters,
"body": app.current_event.body,
"requestContext": app.current_event.request_context,
"httpMethod": app.current_event.http_method,
"path": app.current_event.path,
}
context = app.lambda_context
if path_params:
event['pathParameters'] = {**event.get('pathParameters', {}), **path_params}
return handler_func(event, context)
次にそれぞれのルーティングの設定と関数の実行です。
ここもimport同様にひたすら、書き込んでいくのですが、importと違って、メソッドごとの関数になるので、うまくAIエディターが空気を読んでくれず、間違い探しがやや面倒でした、、、
実行ファイルは先程定義したexecute_handlerを通して実行します。
# ルーティングと関数の実行
# sites
@app.get("/sites")
@tracer.capture_method(capture_response=False)
def get_sites_all():
return execute_handler(get_sites_all_handler)
@app.get("/sites/branch/<branch_code>")
@tracer.capture_method(capture_response=False)
def get_sites_branch(branche_code):
path_params = {'branch_code': branch_code}
return execute_handler(get_sites_branch_handler, path_params)
@app.get("/sites/<site_id>/members")
@tracer.capture_method(capture_response=False)
def get_site_members(site_id):
path_params = {'site_id': site_id}
return execute_handler(get_site_members_handler, path_params)
最後にこのLambdalithの実行ファイル本体です。
実際のファイルはimport文やルーティングの定義がかなり長文なコードになってますが、本体としてはこの関数になります。
定義したルーティングごとの処理は、api_lambda_ersponseで実行されています。
また、ここでもLambda関数から通常の外部関数実行になったことで、json_perseなどの共通処理を考慮して、parse_body()やresponse_builder()でこれまでと同じレスポンスとなるようにしています。
# Lambdalith関数の本体
@logger.inject_lambda_context(correlation_id_path=correlation_paths.API_GATEWAY_REST)
@tracer.capture_lambda_handler(capture_response=False)
def lambda_handler(event: dict, context: LambdaContext) -> dict:
executed_path = event['requestContext']['path']
http_method = event['httpMethod']
api_lambda_response = app.resolve(event, context)
response_body = parse_body(api_lambda_response['body'])
response = response_builder(response_body['statusCode'], response_body['body'])
return response
parse関連のファイル定義
excuse_handlerはlambdalith内で定義しているのに、parse関連は外部ファイルとして定義しており、統一感がないですが、以下のようなparse関数を作成しています。
import json
import logging
import decimal
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def parse_body(body):
"""リクエストBodyをパースする."""
return json.loads(body)
def response_builder(status_code, body={}):
"""APIレスポンスを生成する."""
if isinstance(body, (dict, list)):
# シリアライズ自体は、python関数側で基本実施済み
body = json.dumps(body, cls=DecimalEncoder)
return {
'statusCode': status_code,
'headers': {
'Content-Type': 'application/json; charset=utf-8',
'Access-Control-Allow-Origin': '*'
},
'body': body
}
class DecimalEncoder(json.JSONEncoder):
"""JSONエンコーダー."""
def default(self, obj):
"""エンコード処理."""
if isinstance(obj, decimal.Decimal):
return int(obj)
return super(DecimalEncoder, self).default(obj)
既存Lambda関数のリファクタリング
既存のLambda関数には基本的に手を加えていません。
INVOKEで別Lambda関数を呼び出し実行している関数に関してのみarnがスタックから受け継ぐことができないので、参照先をリファクタリングしました。
また、これまではAPIによってはVPC外Lambda関数として定義したものがありましたが、LambdalithとすることですべてVPC内になりますので、一部リファクタリングをしました。
基本的にはAWSのほかサービスを実行するためにVPC外Lambda関数として定義したのですが、これらのサービスを実行するLambda関数は別途作成して、今回のLambdalithからINVOKE関数として呼び出す方式にしています。
Lambdalithの懸念点
これで無事Lambdalith化が完了して、リソース不足の心配をすることがなくなりましたが、Lambdalithとすることで以下のような懸念が出てきます。
- Lambda関数のパッケージサイズ250MB超過
- CloudwatchLogsなどのエラーハンドリングが共通化
- Lambda関数定義の統一

Lambda関数のパッケージサイズ250MBの超過懸念
まずは、Lambda関数のパッケージサイズ250MBの超過懸念です。
これまで、1API×1Lambda関数となっていたものが一つの関数になるため、Lambda関数としてのパッケージサイズが当然大きくなります。
ただ、現状のコードを全文置き換えた程度ではこの250MBを超えることは基本的にないかなと思います。250MBを超えるような場合は外部モジュールを追加するときくらいでしょうか。
この場合はDocker経由でECRイメージからLambda関数をデプロイすればいいので、lambdalith自体による影響はないと思います。
エラーログの共通化
次に、lambda関数が一つになるので、当然エラーログも一つのものにまとめられてしまいます。
これまでエラーログの戦略をあまり考えていなかったので、今回この懸念が一番厄介でした。
これまではエラーが生じていた場合は、該当の関数からERROR検索していたのですが、一つのLambda関数となったことでログが大量に残っており、人力で探すのはほぼ不可能です。
これまでのやり方が間違っていることが明白なので、この点に関しては、powertoolsの機能をしっかりと勉強し直して、エラーログの検索を容易にできる事自体が、lambdalith移行に関係なく重要なことであったと思います。
Lambda関数定義統一による懸念
最後の懸念はLambda関数が統一になることです。
これまではAPIごとに定義できていたので、例えば処理が重い場合はCPUサイズをおおきくしたり、外部APIや他AWSサービスだけを実行するAPI LambdaはVPC外に配置するなど柔軟に対応していました。
これらのうち、他AWSサービスを実行していたLambda関数については上述した通り、リファクタリングしました。
ただ、CPUサイズについては基本的に懸念点になり得ないかなと思いました。
API Gatewayとしている時点で、29秒のレスポンス制約がありますし、AI関連のサービスでもないものであればAPIレスポンスが10秒でもユーザーは待てないと思います。 そこまで重い処理をAPI Lambdaで実行させること自体が設計が悪いかなと感じました。
おわりに
既存のAPI Lambdaを極力手を加えず、Lambdalithに移行していきました。
社内の内製アプリで、開発当初はミニマムなアプリケーションでしたが、内製化のメリットととして、挑戦的な新機能も比較的容易に実装できるということから多くのAPIが増えていきました。
リソースを分けることも手間と考え、この機会にLambdalithの構成に置き換えることにしました。
ただ、ちょうどこの作業をしているのと同じ時期にServerlessFrameworkがV4から有料化することも発表されてしました。
一度、ServerlessFrameworkのままLambdalithへの移行を急ぎ、将来的にはAWS CDKにプロジェクトごとを再度作り変えることを計画中です。
lambdalithの定義全文


# 共通のパッケージ
import requests
from requests import Response
from aws_lambda_powertools import Logger, Tracer
from aws_lambda_powertools.event_handler import APIGatewayRestResolver
from aws_lambda_powertools.logging import correlation_paths
from aws_lambda_powertools.utilities.typing import LambdaContext
from src._utils.response_utility import response_builder, parse_body
# ソースコード
# #---既存APIのルートパスに合わせて整理しておく。
# #---既存はすべてhandlerなのでリネームしておく。
# /sites
from src.sites.get_sites import handler as get_sites_handler
from src.sites.get_sites_branch import handler as get_sites_branch_handler
from src.sites.get_site_members import handler as get_site_members_handler
# /tasks
from src.tasks.get_tasks_all import handler as get_tasks_all_handler
from src.tasks.get_tasks_bookmark import handler as get_tasks_bookmark_handler
# ...import以下略
tracer = Tracer()
logger = Logger()
app = APIGatewayRestResolver()
# 共通メソッド:ハンドラの呼び出しとパスパラメータの付与
# #---既存Lambda関数を再利用のため、event, contextを同じように統一。
def execute_handler(handler_func, path_params=None):
# app.current_eventを直接操作できないので、別のオブジェクトとして作成
event = {
"headers": app.current_event.headers,
"queryStringParameters": app.current_event.query_string_parameters,
"pathParameters": app.current_event.path_parameters,
"body": app.current_event.body,
"requestContext": app.current_event.request_context,
"httpMethod": app.current_event.http_method,
"path": app.current_event.path,
}
context = app.lambda_context
if path_params:
event['pathParameters'] = {**event.get('pathParameters', {}), **path_params}
return handler_func(event, context)
# ルーティングと関数の実行
# sites
@app.get("/sites")
@tracer.capture_method(capture_response=False)
def get_sites_all():
return execute_handler(get_sites_all_handler)
@app.get("/sites/branch/<branch_code>")
@tracer.capture_method(capture_response=False)
def get_sites_branch(branche_code):
path_params = {'branch_code': branch_code}
return execute_handler(get_sites_branch_handler, path_params)
@app.get("/sites/<site_id>/members")
@tracer.capture_method(capture_response=False)
def get_site_members(site_id):
path_params = {'site_id': site_id}
return execute_handler(get_site_members_handler, path_params)
# tasks
@app.get("/tasks")
@tracer.capture_method(capture_response=False)
def get_task_all():
return execute_handler(get_task_all_handler)
@app.get("/tasks/bookmark/<user_id>")
@tracer.capture_method(capture_response=False)
def get_tasks_bookmark(user_id):
path_params = {'user_id': user_id}
return execute_handler(get_tasks_bookmark_handler, path_params)
# Lambdalith関数の本体
@logger.inject_lambda_context(correlation_id_path=correlation_paths.API_GATEWAY_REST)
@tracer.capture_lambda_handler(capture_response=False)
def lambda_handler(event: dict, context: LambdaContext) -> dict:
executed_path = event['requestContext']['path']
http_method = event['httpMethod']
api_lambda_response = app.resolve(event, context)
response_body = parse_body(api_lambda_response['body'])
response = response_builder(response_body['statusCode'], response_body['body'])
return response
Parse関連ファイル全文
import json
import logging
import decimal
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def parse_body(body):
"""リクエストBodyをパースする."""
return json.loads(body)
def response_builder(status_code, body={}):
"""APIレスポンスを生成する."""
if isinstance(body, (dict, list)):
# シリアライズ自体は、python関数側で基本実施済み
body = json.dumps(body, cls=DecimalEncoder)
return {
'statusCode': status_code,
'headers': {
'Content-Type': 'application/json; charset=utf-8',
'Access-Control-Allow-Origin': '*'
},
'body': body
}
class DecimalEncoder(json.JSONEncoder):
"""JSONエンコーダー."""
def default(self, obj):
"""エンコード処理."""
if isinstance(obj, decimal.Decimal):
return int(obj)
return super(DecimalEncoder, self).default(obj)

コメント